Sample rate: 44100 Hz
Duration: 3.73 seconds
Number of samples: 164375
This notebook demonstrates nonlinear system identification using polynomial lifting to learn a nonlinear distortion system. We’ll use real guitar audio as input and a synthetic nonlinear system based on the hype rbolic tangent (tanh) function to create a controlled learning scenario.
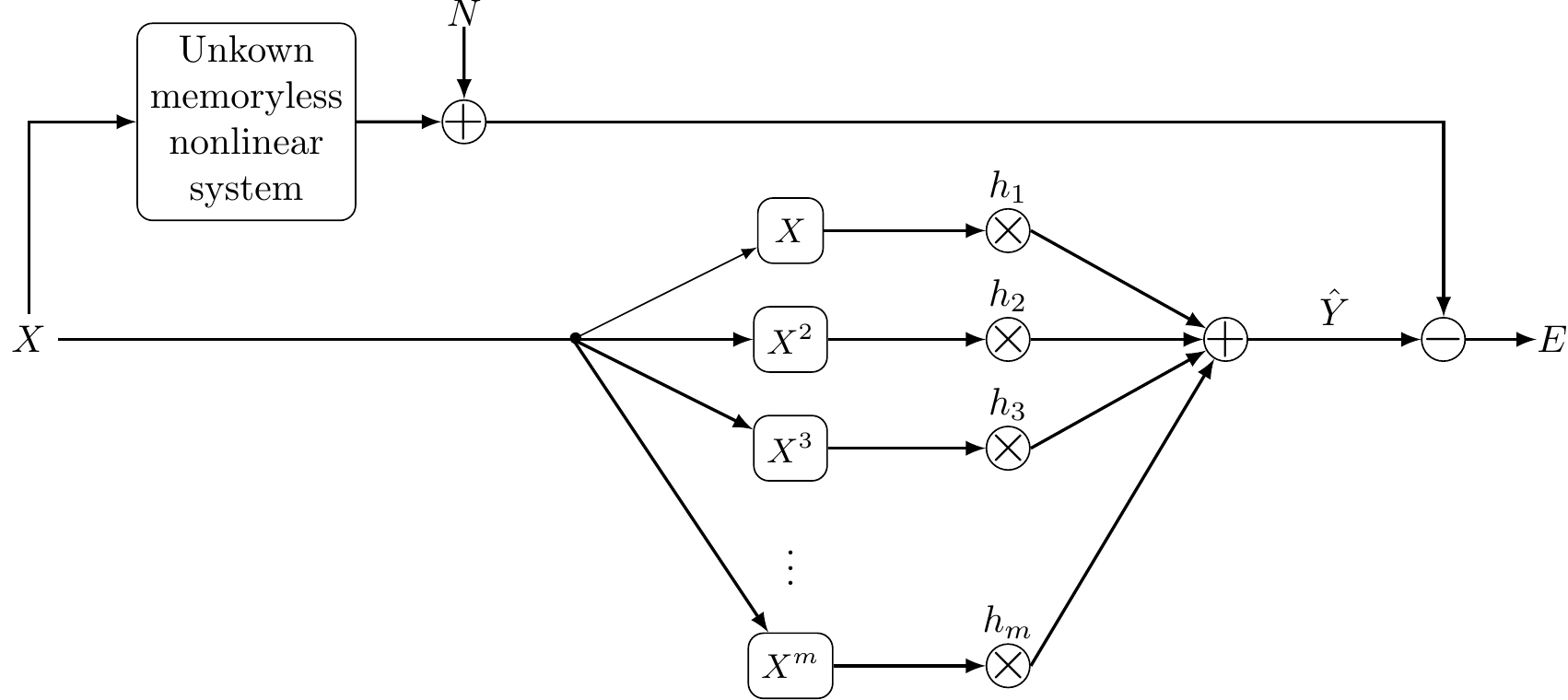
We consider a memoryless nonlinear system that applies a hyperbolic tangent distortion:
y[k] = \tanh(\alpha \cdot x[k]) + n[k]
where:
Why tanh? The hyperbolic tangent function is commonly used to model:
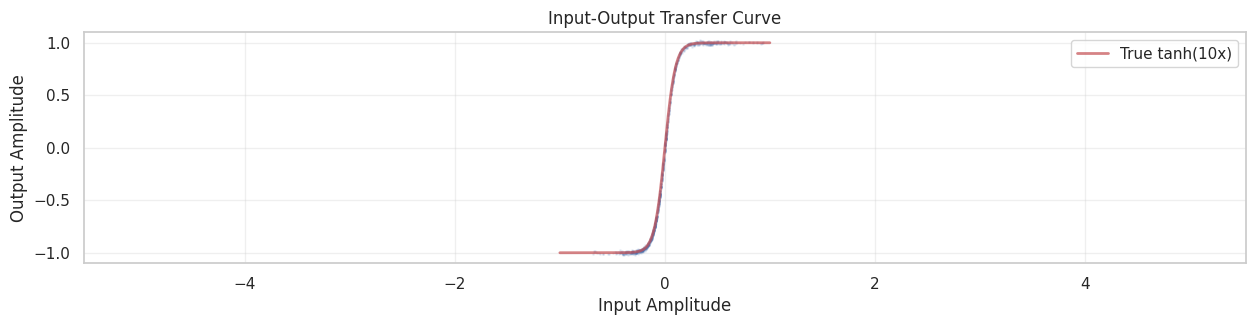
The tanh function has the key property that it saturates for large inputs: as |x| \to \infty, we have |\tanh(x)| \to 1. This creates the characteristic “soft clipping” distortion heard in many guitar effects.
Guitar signals are ideal for this demonstration because:
Our goal is to identify the nonlinear system using only input-output pairs (x[k], y[k]) without knowing the underlying tanh function. We’ll use polynomial lifting with Legendre polynomials to approximate the nonlinearity.
Sample rate: 44100 Hz
Duration: 3.73 seconds
Number of samples: 164375
Now we’ll use polynomial lifting to learn the nonlinear system. The key idea is to:
For a memoryless nonlinear system, we approximate:
\hat{y}[k] = \sum_{m=0}^{M} h_m \cdot x^m[k]
The lifting scheme with the monomials x^m leads to highly correlated features. To avoid this, an alternative lifting scheme is
\hat{y}[k] = \sum_{m=0}^{M} h_m \cdot P_m(x[k])
where P_m(\cdot) are Legendre polynomials of order m, and h_m are the filter coefficients we need to learn.
In matrix form, with N samples:
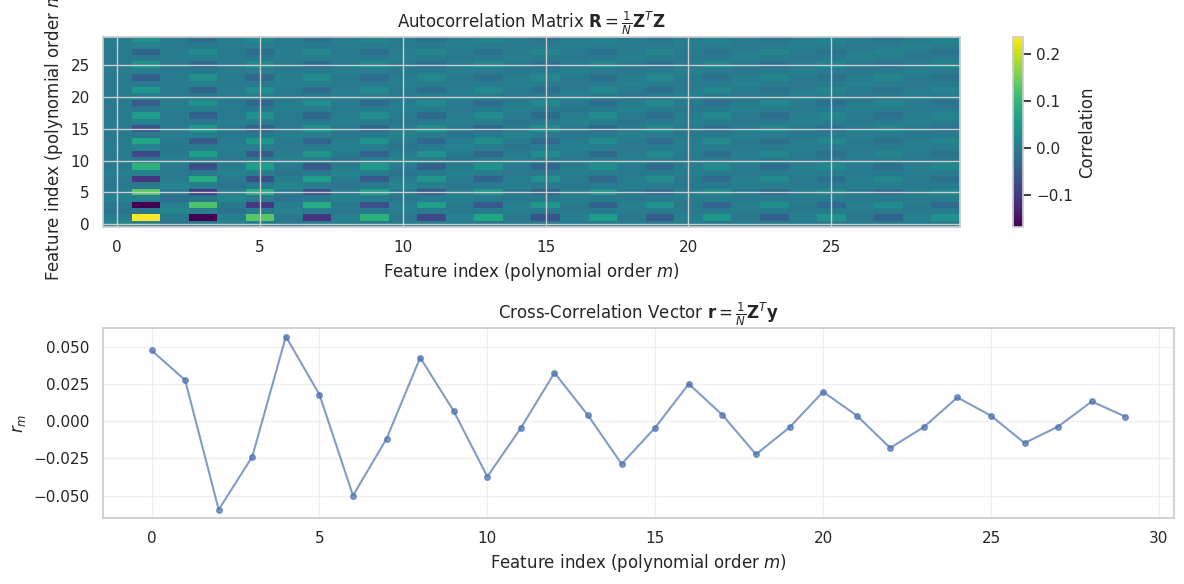
We solve for \mathbf{h} using the normal equation:
\mathbf{R} \mathbf{h} = \mathbf{r}
where:
Training on 150000 samples
Using Legendre polynomials up to order 30
Feature matrix shape: (150000, 30)
Number of features: 30
Autocorrelation matrix shape: (30, 30)<Figure size 1400x1000 with 0 Axes>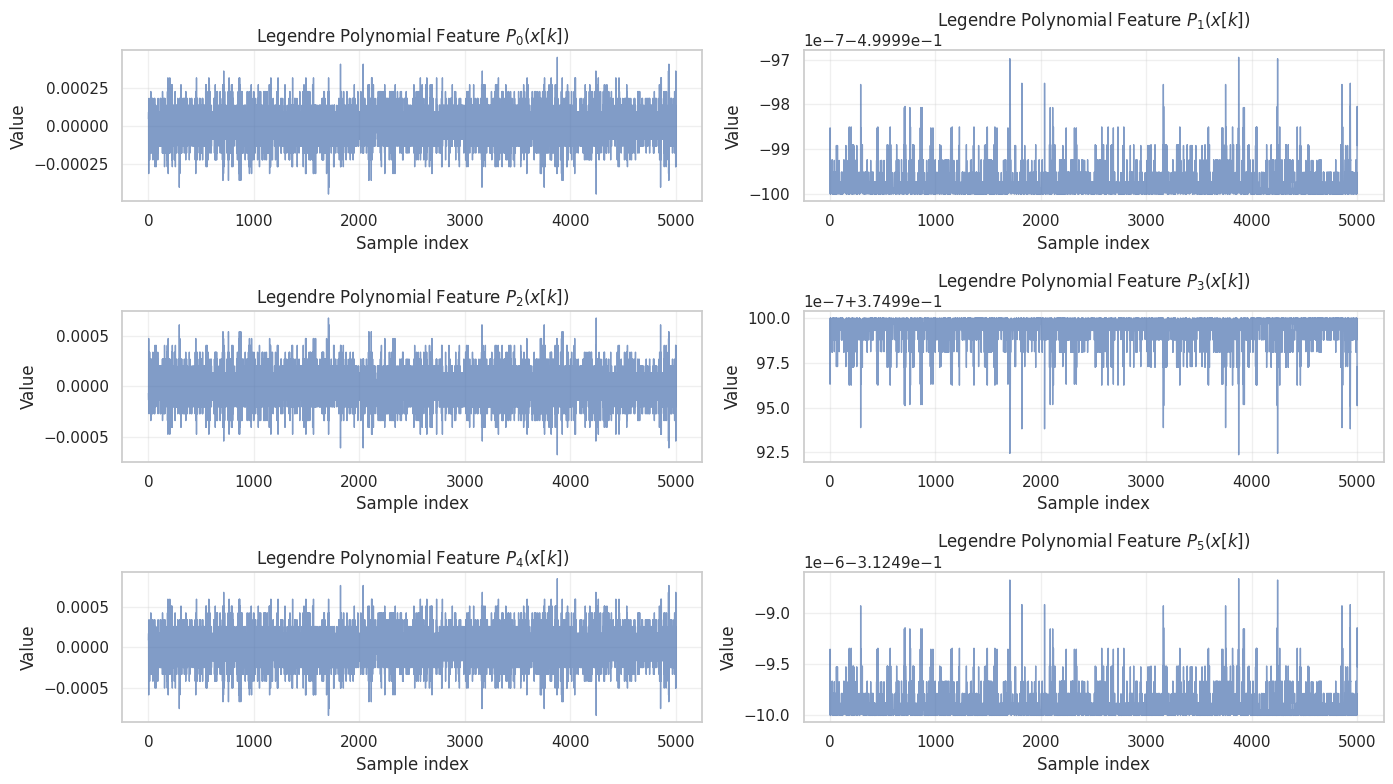
Filter coefficients computed
Total filter parameters: 30
Filter norm: 105.5414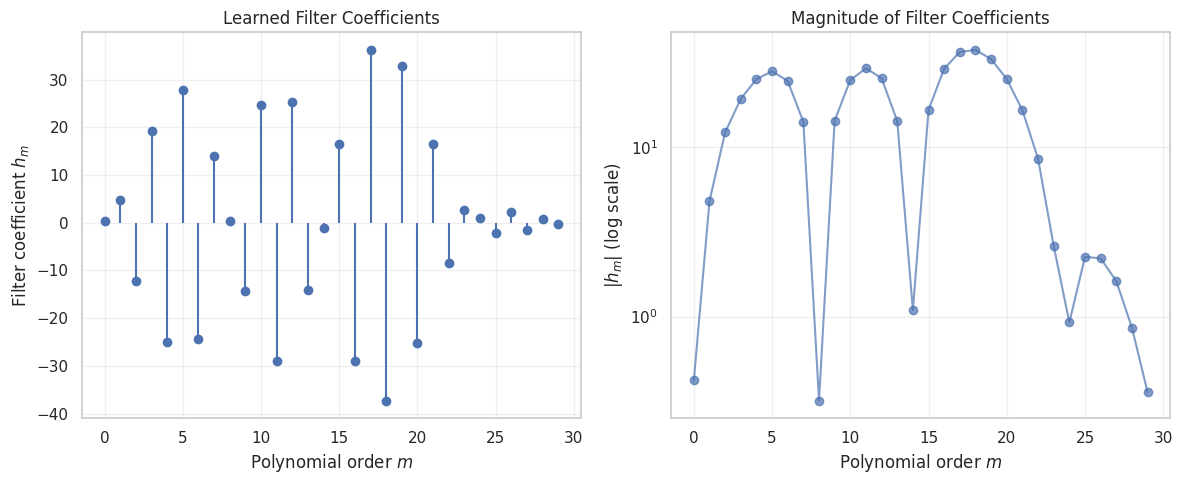
Performance Metrics:
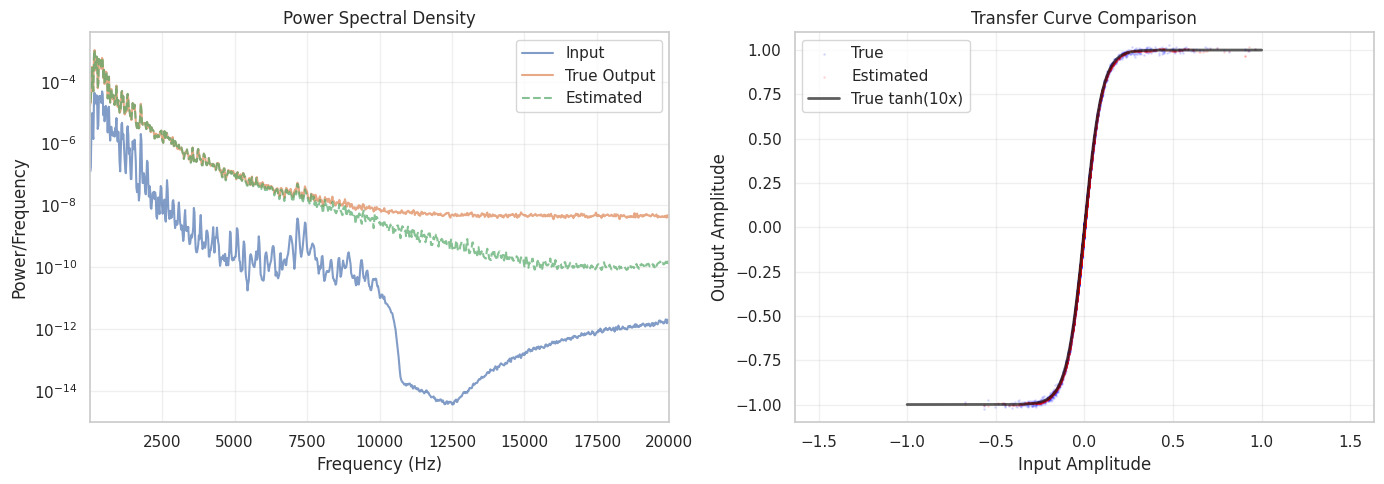
Mean Squared Error (MSE): 0.000103
Root Mean Squared Error (RMSE): 0.010160
Signal-to-Noise Ratio (SNR): 33.42 dB