Is the estimator optimal?
One way to define the optimality of an estimator is uniformly minimum variance and unbiased estimators (UMVUE), i.e.,
- among all unbiased estimators
- this estimator has the lowest variance
- for any true parameter value \theta
A systematic way to derive UMVUE uses the Lehmann–Scheffé theorem, but this is typically more involved (and outside the scope here).
However, MLE is a good recipe to derive estimators. MLE does not guarantee UMVUE. The MLE is however optimal in an asymptotic sense, i.e., for large‐sample sizes:
- Consistency: \hat\theta_{\text{MLE}}\to\theta (under mild conditions).
- Asymptotic normality: \sqrt{n}(\hat\theta_{\text{MLE}}-\theta)\xrightarrow{d} \mathcal{N}(0,I(\theta)^{-1})
- Asymptotic efficiency: it attains the CRLB as n\to\infty.
Alternatively, one can test whether an unbiased estimator is UMVUE by checking whether it achieves the CRLB. If an unbiased estimator achieves the CRLB, then it is UMVUE. But, because the CRLB requires certain regularity conditions, the converse is not true: an estimator can be UMVUE without achieving the CRLB.
The diagram shows a conceptual overview on the hierarchy of estimators. 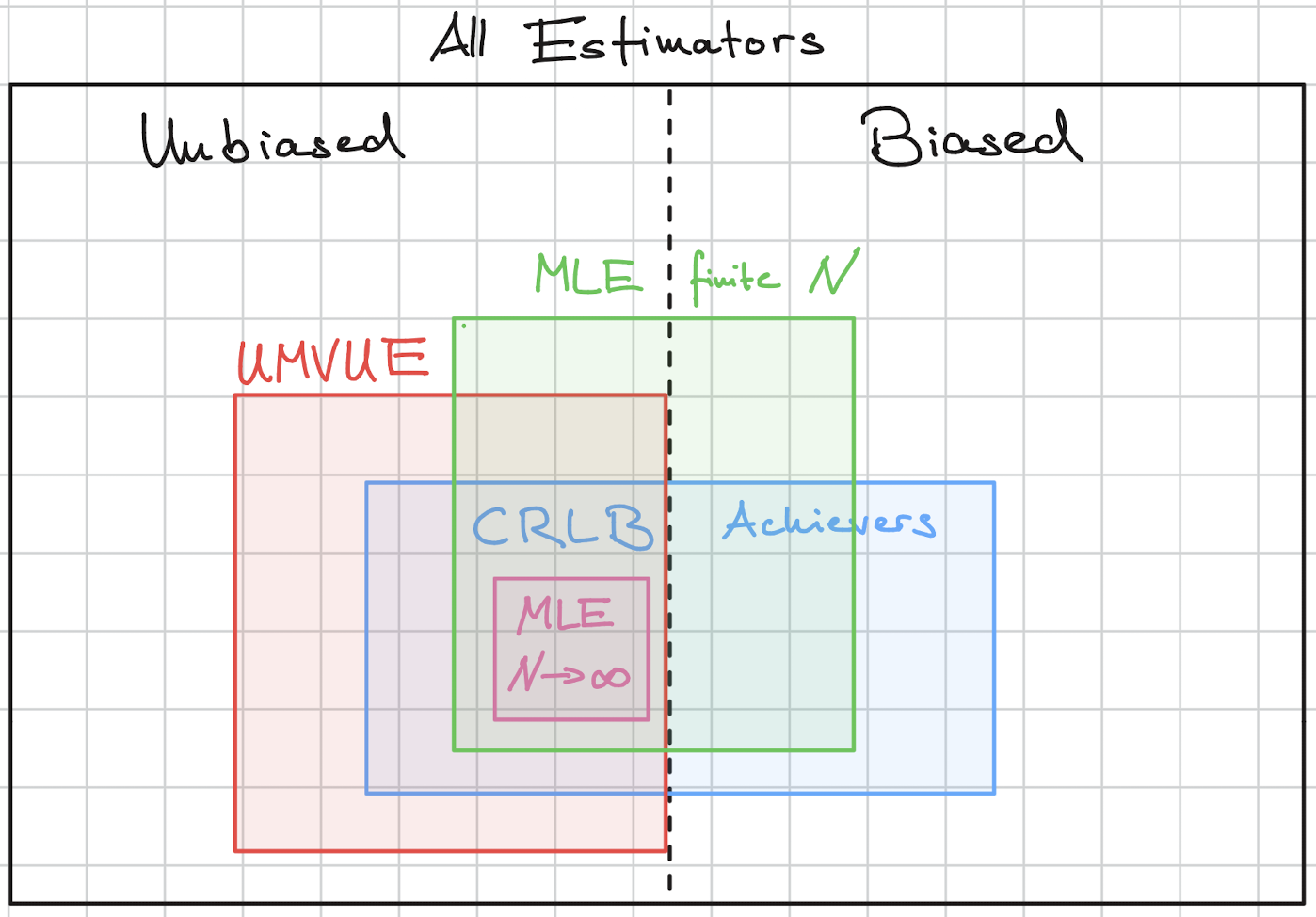
Is unbiasedness desirable?
The UMVUE finds the lowest variance estimator among all unbiased estimators. While unbiasedness is a desirable property, it constrains the search space and may result in higher variance.
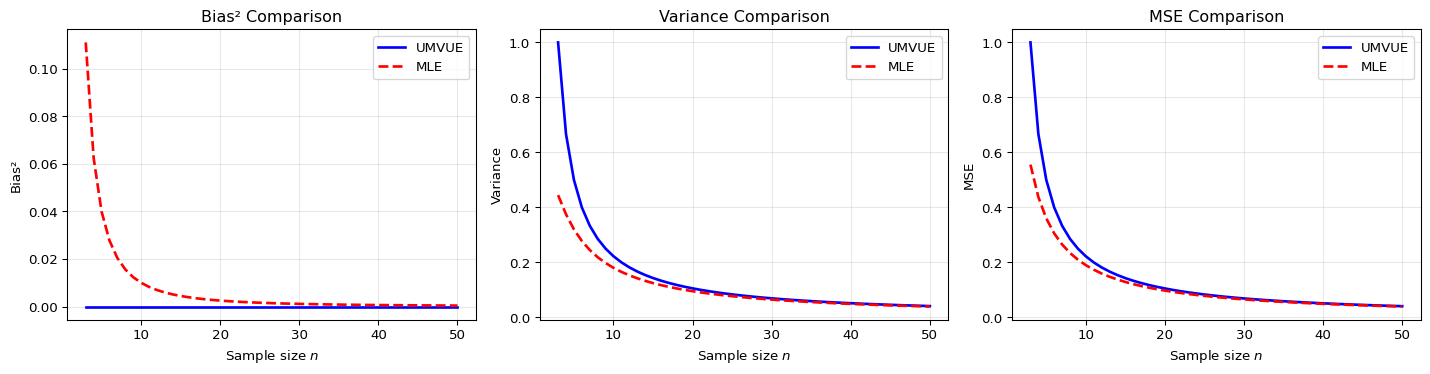
In contrast, biased estimators (like the MLE) can trade some bias for reduced variance, potentially achieving a smaller Mean Squared Error (MSE), since MSE = variance + bias².
We present an example comparing the UMVUE and MLE to illustrate this bias-variance tradeoff.
Example: Estimating the variance of a Gaussian
Data: X_1,\dots,X_n \sim \mathcal N(\mu,\sigma^2).
Parameter of interest: \sigma^2.
UMVUE
The unbiased estimator is \hat\sigma^2_{\mathrm{UMVUE}} = \frac{1}{n-1} \sum_{i=1}^n (X_i - \bar X)^2.
Variance: \operatorname{Var}(\hat\sigma^2_{\mathrm{UMVUE}}) = \frac{2\sigma^4}{n-1}.
MLE
The MLE is biased: \hat\sigma^2_{\mathrm{MLE}} = \frac{1}{n} \sum_{i=1}^n (X_i - \bar X)^2 = \frac{n-1}{n} \hat\sigma^2_{\mathrm{UMVUE}}.
Its bias: \mathrm{Bias} = -\frac{\sigma^2}{n}.
Variance: \operatorname{Var}(\hat\sigma^2_{\mathrm{MLE}}) = \left(\frac{n-1}{n}\right)^2 \frac{2\sigma^4}{n-1} = \frac{2\sigma^4(n-1)}{n^2}.
Compare MSEs
UMVUE MSE: \mathrm{MSE}(\hat\sigma^2_{\mathrm{UMVUE}}) = \frac{2\sigma^4}{n-1}.
MLE MSE: \mathrm{MSE}(\hat\sigma^2_{\mathrm{MLE}}) = \frac{2\sigma^4(n-1)}{n^2} + \left(\frac{\sigma^2}{n}\right)^2.
One can check that: \mathrm{MSE}(\hat\sigma^2_{\mathrm{MLE}}) < \mathrm{MSE}(\hat\sigma^2_{\mathrm{UMVUE}}) \qquad \text{for all } n\ge 2.